Muduo源码笔记系列:
muduo源码阅读笔记(0、下载编译muduo)
muduo源码阅读笔记(1、同步日志)
muduo源码阅读笔记(2、对C语言原生的线程安全以及同步的API的封装)
muduo源码阅读笔记(3、线程和线程池的封装)
muduo源码阅读笔记(4、异步日志)
muduo源码阅读笔记(5、Channel和Poller)
muduo源码阅读笔记(6、ExevntLoop和Thread)
muduo源码阅读笔记(7、EventLoopThreadPool)
muduo源码阅读笔记(8、定时器TimerQueue)
muduo源码阅读笔记(9、TcpServer)
muduo源码阅读笔记(10、TcpConnection)
前言
与base文件夹下的通用线程池相比,EventLoopThreadPool更加专门化,专为为EventLoopThread而生,专为EventLoop而生,专为One Loop Per Thread而生,专为网络事件驱动而生,专为Muduo而生!
实现
提供的接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| class EventLoopThreadPool : noncopyable{
public:
typedef std::function<void(EventLoop*)> ThreadInitCallback;
EventLoopThreadPool(EventLoop* baseLoop, const string& nameArg);
~EventLoopThreadPool();
void setThreadNum(int numThreads) { numThreads_ = numThreads; }
void start(const ThreadInitCallback& cb = ThreadInitCallback());
EventLoop* getNextLoop();
EventLoop* getLoopForHash(size_t hashCode);
std::vector<EventLoop*> getAllLoops();
bool started() const
{ return started_; }
const string& name() const
{ return name_; }
private:
EventLoop* baseLoop_;
string name_;
bool started_;
int numThreads_;
int next_;
std::vector<std::unique_ptr<EventLoopThread>> threads_;
std::vector<EventLoop*> loops_;
};
|
结合muduo源码阅读笔记(6、ExevntLoop和Thread)简单画了一下EventLoopThreadPool的架构图:
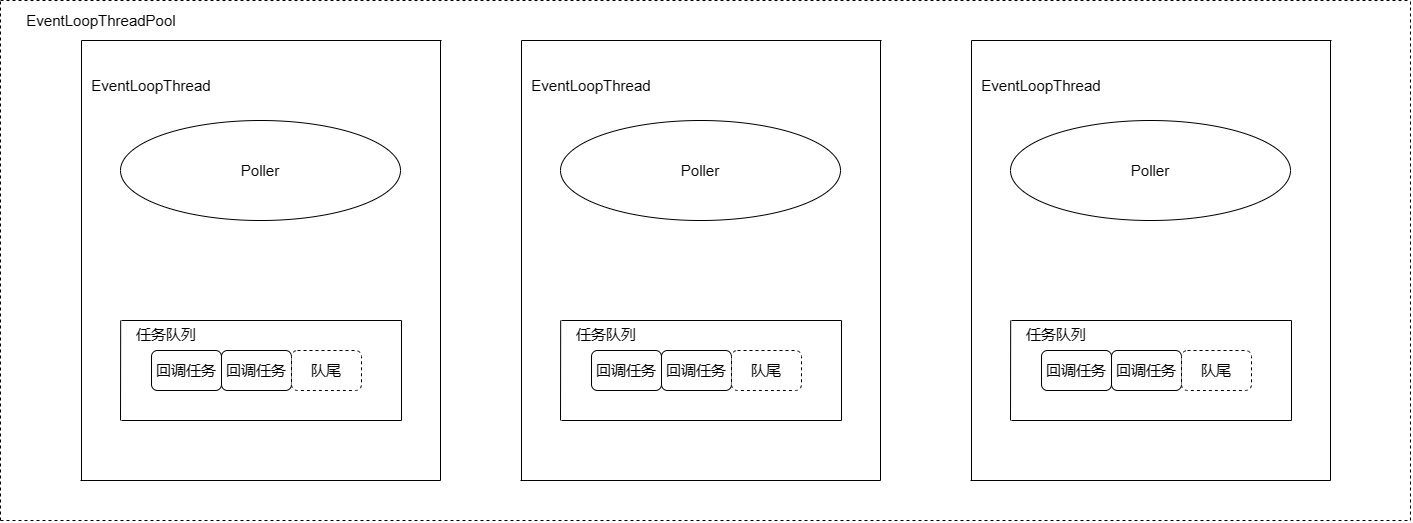
实现的伪代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| EventLoopThreadPool::EventLoopThreadPool(EventLoop* baseLoop, const string& nameArg)
: baseLoop_(baseLoop),
name_(nameArg),
started_(false),
numThreads_(0),
next_(0){
}
EventLoopThreadPool::~EventLoopThreadPool(){
}
void EventLoopThreadPool::start(const ThreadInitCallback& cb){
assert(!started_);
baseLoop_->assertInLoopThread();
started_ = true;
for (int i = 0; i < numThreads_; ++i){
char buf[name_.size() + 32];
snprintf(buf, sizeof buf, "%s%d", name_.c_str(), i);
EventLoopThread* t = new EventLoopThread(cb, buf);
threads_.push_back(std::unique_ptr<EventLoopThread>(t));
loops_.push_back(t->startLoop());
}
if (numThreads_ == 0 && cb){
cb(baseLoop_);
}
}
EventLoop* EventLoopThreadPool::getNextLoop(){
baseLoop_->assertInLoopThread();
assert(started_);
EventLoop* loop = baseLoop_;
if (!loops_.empty()){
loop = loops_[next_];
++next_;
if (implicit_cast<size_t>(next_) >= loops_.size()){
next_ = 0;
}
}
return loop;
}
EventLoop* EventLoopThreadPool::getLoopForHash(size_t hashCode){
baseLoop_->assertInLoopThread();
EventLoop* loop = baseLoop_;
if (!loops_.empty()){
loop = loops_[hashCode % loops_.size()];
}
return loop;
}
std::vector<EventLoop*> EventLoopThreadPool::getAllLoops(){
baseLoop_->assertInLoopThread();
assert(started_);
if (loops_.empty()){
return std::vector<EventLoop*>(1, baseLoop_);
}else{
return loops_;
}
}
|
细节明细
疑问:
关于EventLoopThreadPool::getNextLoop()、EventLoopThreadPool::getLoopForHash的作用?
解答:
小到线程之间,大到服务器集群之间,都需要保证负载均衡,以免大量的连接集中在某一个线程或者某一台机器,导致压力过大,而使连接任务无法有效处理。
疑问:
Muduo为什么大量使用unique_ptr智能指针,而不是使用sahred_ptr智能指针?
以下是一些可能的原因:
所有权的清晰性: std::unique_ptr表示独占所有权,这意味着每个指针拥有对其指向对象的唯一所有权。这种所有权模型有助于明确代码中哪个部分负责释放资源。
线程安全性: Muduo是一个面向多线程的网络库,而std::shared_ptr的引用计数是原子操作,可能在高并发环境下带来额外的竞争,从而影响性能。相比之下,std::unique_ptr的独占所有权模型更适合并发环境。
性能开销: std::shared_ptr通常会维护一个引用计数,用于跟踪共享对象的所有权信息。这样的引用计数可能引入额外的性能开销,特别是在高并发的网络编程场景下,性能是一个关键因素。
避免循环引用: 使用std::shared_ptr可能导致循环引用的问题,特别是在涉及到复杂的对象关系时。这可能导致资源无法被释放,从而引发内存泄漏。
本章完结
