muduo源码阅读笔记(0、下载编译muduo)
muduo源码阅读笔记(1、同步日志)
muduo源码阅读笔记(2、对C语言原生的线程安全以及同步的API的封装)
muduo源码阅读笔记(3、线程和线程池的封装)
muduo源码阅读笔记(4、异步日志)
muduo源码阅读笔记(5、Channel和Poller)
muduo源码阅读笔记(6、ExevntLoop和Thread)
muduo源码阅读笔记(7、EventLoopThreadPool)
muduo源码阅读笔记(8、定时器TimerQueue)
muduo源码阅读笔记(9、TcpServer)
muduo源码阅读笔记(10、TcpConnection)
闲聊
Muduo对线程和线程池的封装,涉及得到源码也不多,大概加一起300多行,这部分读者可以好好精读一下。
线程 在阅读cpp的源码,分析一个类具体的实现的时候,首先应该看类的.h文件,主要看类的成员变量有哪些,毕竟成员函数,就是对成员变量进行代码层面的操作的。
提供的接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Thread : noncopyable {public : typedef std::function<void ()> ThreadFunc; explicit Thread (ThreadFunc, const string& name = string()) ~Thread (); void start () int join () bool started () const return started_; } pid_t tid () const return tid_; } const string& name () const return name_; } static int numCreated () return numCreated_.get (); } private : void setDefaultName () bool started_; bool joined_; pthread_t pthreadId_; pid_t tid_; ThreadFunc func_; string name_; CountDownLatch latch_; static AtomicInt32 numCreated_; };
线程启动流程:
Thread::start() ->
pthread_create(…, &detail::startThread,…) ->
startThread(void* obj) ->
ThreadData::runInThread() ->
Thread::func_()
实现的伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 struct ThreadData { typedef muduo::Thread::ThreadFunc ThreadFunc; ThreadFunc func_; string name_; pid_t * tid_; CountDownLatch* latch_; ThreadData (ThreadFunc func, const string& name, pid_t * tid, CountDownLatch* latch) : func_ (std::move (func)), name_ (name), tid_ (tid), latch_ (latch) { } void runInThread () *tid_ = muduo::CurrentThread::tid (); tid_ = NULL ; latch_->countDown (); latch_ = NULL ; muduo::CurrentThread::t_threadName = name_.empty () ? "muduoThread" : name_.c_str (); ::prctl (PR_SET_NAME, muduo::CurrentThread::t_threadName); try { func_ (); muduo::CurrentThread::t_threadName = "finished" ; } catch (...){ } } }; void * startThread (void * obj) ThreadData* data = static_cast <ThreadData*>(obj); data->runInThread (); delete data; return NULL ; } Thread::Thread (ThreadFunc func, const string& n) : started_ (false ), joined_ (false ), pthreadId_ (0 ), tid_ (0 ), func_ (std::move (func)), name_ (n), latch_ (1 ){ setDefaultName (); } Thread::~Thread (){ if (started_ && !joined_){ pthread_detach (pthreadId_); } } void Thread::setDefaultName () int num = numCreated_.incrementAndGet (); if (name_.empty ()){ char buf[32 ]; snprintf (buf, sizeof buf, "Thread%d" , num); name_ = buf; } } void Thread::start () assert (!started_); started_ = true ; detail::ThreadData* data = new detail::ThreadData (func_, name_, &tid_, &latch_); if (pthread_create (&pthreadId_, NULL , &detail::startThread, data)){ started_ = false ; delete data; LOG_SYSFATAL << "Failed in pthread_create" ; }else { latch_.wait (); assert (tid_ > 0 ); } } int Thread::join () assert (started_); assert (!joined_); joined_ = true ; return pthread_join (pthreadId_, NULL ); }
细节明细: 疑问:
Muduo网络库在封装Thread时,为什么不直接向子线程传递Thread对象本身,反而去创建一个ThreadData对象去传递呢?
解答:
Muduo网络库在封装Thread时选择创建一个ThreadData对象而不是直接向子线程传递Thread对象本身,有一些合理的设计考虑:
线程安全性: 直接向子线程传递Thread对象可能会引入线程安全的问题。Thread对象的生命周期和线程的执行是相关联的,如果在子线程中直接访问或修改Thread对象,可能导致竞态条件和不确定的行为。通过ThreadData的设计,可以更好地封装线程私有数据,确保线程安全性。
封装线程私有数据: ThreadData的存在允许封装线程私有数据,这些数据对于特定线程是独立的。如果直接传递Thread对象,就需要确保Thread对象的成员变量在多线程环境下的正确性和安全性,而通过ThreadData可以更容易实现这一点。
用户数据传递: ThreadData允许用户在创建线程时传递额外的用户数据。这使得用户可以通过ThreadData传递一些上下文信息,而不必直接依赖Thread对象。
解耦设计: 通过ThreadData的设计,Thread类的内部实现与线程的具体执行逻辑解耦。Thread对象可以专注于线程的管理,而线程的执行逻辑则通过ThreadData实现,提高了代码的模块化和可维护性。
Muduo中,对Posix线程调用fork函数的处理:
背景: 我有写过一个deamo,结果表明,posix线程在调用fork后,子进程并不会复制父进程的所有线程,即子进程只有一个线程(也是子线程的主线程),该线程就是父进程调用fork函数的子线程的上下文复制版。
Muduo中的处理: Muduo设计了一个ThreadNameInitializer类,该类定义了一个全局对象,在程序创建时,构造函数会调用pthread_atfork函数,设置了chile回调afterFork(),在子进程被创建时,系统会调用afterFork()回调,重新设置子进程中主线程的线程局部变量包括:t_cachedTid、t_threadName等。
回调代码如下:
1 2 3 4 5 6 void afterFork () muduo::CurrentThread::t_cachedTid = 0 ; muduo::CurrentThread::t_threadName = "main" ; CurrentThread::tid (); }
线程池 Muduo设计的线程池,可以直接当模板来使用,设计的非常精妙。不仅线程池的初始化和运行,而且线程池的析构停止 做的也非常清晰。
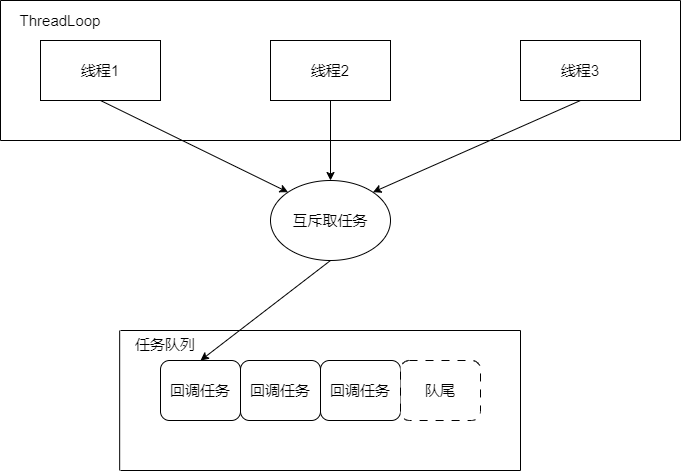
架构图:
线程池的每个线程执行的线程回调,都是处于一个while循环中,循环往复的执行:
到任务队列取回调任务。
执行回调任务。
回到1。
当然,如果线程池停止了,就会跳出循环。
提供的接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class ThreadPool : noncopyable{public : typedef std::function<void ()> Task; explicit ThreadPool (const string& nameArg = string("ThreadPool" )) ~ThreadPool (); void setMaxQueueSize (int maxSize) void setThreadInitCallback (const Task& cb) { threadInitCallback_ = cb; } void start (int numThreads) void stop () const string& name () const { return name_; } size_t queueSize () const void run (Task f) private : bool isFull () const REQUIRES (mutex_) void runInThread () Task take () ; mutable MutexLock mutex_; Condition notEmpty_ GUARDED_BY (mutex_) ; Condition notFull_ GUARDED_BY (mutex_) ; string name_; Task threadInitCallback_; std::vector<std::unique_ptr<muduo::Thread>> threads_; std::deque<Task> queue_ GUARDED_BY (mutex_) ; size_t maxQueueSize_; bool running_; };
注意:
线程池中,在调用ThreadPool::start()启动线程池之前,必须先调用ThreadPool::setMaxQueueSize来设定任务队列的最大任务数。
实现的伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 ThreadPool::ThreadPool (const string& nameArg) : mutex_ (), notEmpty_ (mutex_), notFull_ (mutex_), name_ (nameArg), maxQueueSize_ (0 ), running_ (false ){ } ThreadPool::~ThreadPool (){ if (running_){ stop (); } } void ThreadPool::start (int numThreads) assert (threads_.empty ()); running_ = true ; threads_.reserve (numThreads); for (int i = 0 ; i < numThreads; ++i){ char id[32 ]; snprintf (id, sizeof id, "%d" , i+1 ); threads_.emplace_back (new muduo::Thread ( std::bind (&ThreadPool::runInThread, this ), name_+id)); threads_[i]->start (); } if (numThreads == 0 && threadInitCallback_){ threadInitCallback_ (); } } void ThreadPool::stop () { MutexLockGuard lock (mutex_) ; running_ = false ; notEmpty_.notifyAll (); notFull_.notifyAll (); } for (auto & thr : threads_){ thr->join (); } } size_t ThreadPool::queueSize () const MutexLockGuard lock (mutex_) ; return queue_.size (); } void ThreadPool::run (Task task) if (threads_.empty ()){ task (); }else { MutexLockGuard lock (mutex_); while (isFull () && running_){ notFull_.wait (); } if (!running_) return ; assert (!isFull ()); queue_.push_back (std::move (task)); notEmpty_.notify (); } } ThreadPool::Task ThreadPool::take () { MutexLockGuard lock (mutex_) ; while (queue_.empty () && running_){ notEmpty_.wait (); } Task task; if (!queue_.empty ()){ task = queue_.front (); queue_.pop_front (); if (maxQueueSize_ > 0 ){ notFull_.notify (); } } return task; } bool ThreadPool::isFull () const mutex_.assertLocked (); return maxQueueSize_ > 0 && queue_.size () >= maxQueueSize_; } void ThreadPool::runInThread () try { if (threadInitCallback_){ threadInitCallback_ (); } while (running_){ Task task (take()) ; if (task){ task (); } } }catch (...){ } }
细节明细: 疑问:
Muduo的线程池中为什么要设置一个maxQueueSize_成员来限制任务队列的大小?
解答:
在Muduo网络库的线程池中设置maxQueueSize_成员来限制任务队列的大小是为了防止无限制的任务积压,以保护系统的稳定性和资源管理。这样的设计有以下几个原因:
资源控制: 通过设置任务队列的最大大小,可以控制线程池在高负载情况下的资源占用。如果不限制任务队列大小,当任务提交速度远远大于线程池处理速度时,可能会导致任务队列无限增长,消耗大量内存资源,最终导致系统资源耗尽。
避免任务积压: 如果任务队列无限制增长,可能导致待处理的任务数量不断累积,进而导致系统的响应时间变长。通过设置最大队列大小,可以避免任务积压,确保系统对任务的响应是有限度的。
反馈机制: 当任务队列达到最大大小时,新的任务可能会被拒绝或者触发一些警告机制。这样的反馈机制可以让开发者或者系统管理员及时感知到系统的负载情况,并采取相应的措施,如调整线程池大小、优化任务处理逻辑等。(尽管在Muduo中,在代码实现上并没有实现这一点 )
疑问:
在ThreadPool::runInThread函数中,如果线程池要停止了(running_ == false),假如任务队列里面还有任务不继续消化任务吗?我看Muduo的实现是,线程池停止,即使任务队列还有任务,ThreadPool::runInThread()也会直接跳出循环。为什么要这样设计?
解答:
线程池的停止有两种:
Graceful Shutdown: 线程池的停止过程可能是优雅的,即允许已经在任务队列中的任务执行完毕,但不再接受新的任务。在这种情况下,可以通过设置running_为false来触发线程池停止,但允许已在队列中的任务继续执行。
快速停止: 另一种设计考虑是快速停止,即立即停止线程的执行,无论任务队列中是否还有任务。这可能是为了迅速释放线程池占用的资源,例如在应用程序关闭时。在这种情况下,即使有未执行的任务,也可以选择快速停止线程池。
具体选择采用哪种停止方式取决于应用程序的需求和设计目标。如果对任务的完成有严格的要求,可以选择优雅停止,确保所有任务得以执行。如果更注重迅速释放资源,可以选择快速停止。
在Muduo中的设计选择了快速停止,一旦running_为false,即使任务队列中还有任务,线程也会直接退出。这种设计可能符合Muduo网络库的使用场景和性能需求。
maxQueueSize_ == 0的特殊含义:
在Muduo网络库中,仔细梳理线程池的源码逻辑可以发现,如果maxQueueSize_的大小被设置为0,表示任务队列的大小没有限制,即队列可以无限增长。ThreadPool::isFull函数会始终返回false,此时在调用ThreadPool::run向任务队列添加任务时,会无条件将任务添加到任务队列,而且ThreadPool::take函数中,由于maxQueueSize_ == 0,也不会去调用notFull_.notify()通知阻塞在ThreadPool::run的线程,因为在maxQueueSize_ == 0条件下根本不可能有线程会阻塞在ThreadPool::run中。
本章完结